
چه زمانی باید به تصمیمات رباتها اعتماد کرد و چه زمانی نباید این کار را انجام داد
درست همانند اینترنت، ماشینهای هوشمند و انطباقپذیر به سرعت در حال تبدیل شدن به بخشی از زندگی روزمره ما هستند. بیشتر تصمیمگیریهای ما با الگوریتمهای هوشمندی اتخاذ میشوند که از حجم روزافزون و متنوعی از دادهها به دست میآیند.
در حالی که این "رباتها" در حال تبدیل شدن به بخش بزرگتری از زندگی ما هستند، ما هنوز هیچ چارچوبی برای ارزیابی این که کدام نوع از تصمیم گیریهایمان را باید به رباتها واگذار کنیم و کدام یک را خود انجام دهیم نداریم. این موضوع حیرتآور است، و باعث به وجود آمدن ریسک بالایی میگردد.
من یک چارچوب ریسک گرا برای تعیین زمان و نحوه تخصیص مسائل تصمیمگیری، بین انسان و تصمیمگیری مبتنی بر ماشین مطرح کردهام. این چارچوب بر اساس تجربیات من و همکارانم در اجرای سیستمهای پیشبینی در طی 25 سال گذشته در حوزههایی مانند امور مالی، بهداشت و درمان، آموزش و پرورش، و ورزش توسعه پیدا کرده است.
این چارچوب مسائل را در دو بعد مستقل قابلیت پیشبینی پذیری و هزینه به ازای هر خطا از هم متمایز میکند.
ابتدا اولین بُعد این چارچوب، ینی قابلیت پیشبینی پذیری را در نظر بگیرید.
قابلیت پیشبینی پذیری به این نکته اشاره دارد که چقدر باید انتظار داشته باشیم که بهترین سیستم پیش بینی بهتر از حالت تصافی عمل کند.

نمودار بالا نمونهای از برخی مسائل درجهبندی شده از لحاظ قابلیت پیشبینی پذیری را نشان میدهد که پیشرفت کنونی در یادگیری ماشین و فناوری هوش مصنوعی را نشان میدهد. منتهی الیه سمت چپ نمودار نشانگر یک پرتاب سکه است که " سیگنال صفر"دارد – منظور فعالیتی است که نتیجه پیشبینی از حالت تصادفی بهتر نخواهد بود-. منتهی الیه سمت راست نشاندهنده مسائل تصمیمگیری مکانیکی است که از قطعیت برخوردارند.
با حرکت از سمت چپ به راست این نمودار، با نمونهای از سرمایهگذاریهای بلند مدت مواجه میشویم که بنا بر شواهد و نظریههای اقتصادی، انسان این این کار را عموماً ضعیفتر از حالت تصادفی انجام میدهد. هرچه میزان پیشبینی کوتاهتر گردد (به عنوان مثال در تجارتهای کوتاه مدت و سپس معاملات پُرتواتر) متعاقب آن پیشبینی پذیری به میزان محدودی افزایش مییابد. با حرکت به سمت راست نمودار خواهیم دید که مواردی مانند تشخیص تقلب در کارتهای اعتباری و یا فیلترینگ هرزنامهها از قابلیت پیشبینیپذیری بالایی برخوردار است، با این وجود سیستمهای کنونی هنوز هم میزان قابل توجهی از خطاهای مثبت و منفی تولید میکنند. در منتهی الیه سمت راست نمودار، با مسائل ساختار یافتهای مواجه میشویم که از بیشترین قابلیت پیشبینی پذیری برخوردارند. برای مثال، خودروهای بدون راننده در محدودههایی فعالیت میکنند که فیزیک مسئله به خوبی شناخته شده است. اگرچه مقداری عدم قطعیت در مورد رفتار سایر وسایل نقلیه و محیط زیست وجود دارد با این حال به طور متوسط این خودروها هنوز هم قابلیت این را دارند که پیشرفت کرده و ایمنتر از انسان رانندگی کنند.
با درجهبندی فعالیتها در این بُعد، کاملا مشحص میگردد که چالشها و فرصتهای ماشینی کردن امور در چه حوزههایی میباشد. با این وجود، اگرچه ممکن است محدود کردن بحث و بررسی در مورد قدرت پیشبینی و این استنباط که " مسائل سیگنال بالا میتوانند توسط رباتها انجام شوند و مسائل فرکانس پایین به حضور انسانها نیاز دارند" وسوسه انگیز به نظر برسد، با این حال این دیدگاه یک بعدی کاستیهایی نیز به همراه دارد. برای این که به درستی نتیجهگیری کنیم که چه تصمیمگیریهایی را باید به رباتها محول کنیم باید عواقب ناشی از هر اشتباه را در نظر بگیریم. متغیری که حداقل اهمیتی برابر و یا حتی بیشتر از دقت پیشبینی دارد.
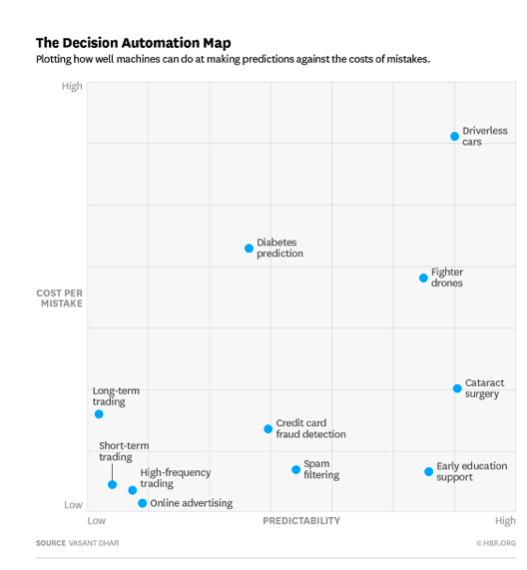
در نمودار دو بعدی و کاملتر بالا (که من آن را DA-MAP مینامم) همانند نمودار قبلی محور افقی نشان دهنده قابلیت پیشبینی پذیری میباشد. هزینه هر خطا،که میتواند به صورت واحد مالی و یا هر واحد دیگری (بسته به نوع مسئله) بیان شود در راستای محور عمودی مشخص شده است.
افزودن این بُعد دوم کمک مهمی به فهم بهتر موضوع خواهد کرد.
دو مسئله با قابلیت پیشبینی پذیری بالا، برای مثال فیلترینگ هرزنامهها و خودروهای بدون راننده را که در قسمت اول بررسی کردیم در نطر بگیرید. فیلترینگ هرزنامه مربوط به نوعی مسئله ایجاد مزاحمت است که در آن افراد فرستنده هرزنامه سعی میکنند سیستم فیلترینگ را فریب دهند. این سیستم طوری تنظیم شده است که محتواهای مشروع را فیلتر نکند، به همین خاطر در صورت عبور برخی هرزنامهها از فیلترینگ، هزینه خطای مثبت در آن باید خیلی ناچیز باشد که البته همین طور نیز هست. در طرف مقابل هزینه یک خطا در خودرو بدون راننده میتواند بسیار بالا باشد. هزینه خطا در تصمیمگیری برای هواپیماهای جنگنده بدون سرنشین (وسط سمت راست نمودار) نیز به وضوح بالاست. تصور کنید این جنگندهها به جای یک انبار مهمات یک بیمارستان را بمباران کنند. اما این مسئله حداقل از دو منظر با مسئله خودروهای بدون راننده تفاوت دارد: اول این که جنگندههای بدون سرنشین در جنگ استفاده میشوند که در آن نسبت به جادههای برون شهری تحمل بیشتری برای خطا وجود دارد، و دوم این که استفاده از آن ها خطر پرواز خلبانان بر فراز منطقه دشمن را به شدت کاهش میدهد.
خطاهای پیشبینی در مراقبتهای بهداشتی نیز هزینه قابل توجهی دارد. برای مثال، عدم پیشبینی دیابت در یک بیمار مبتلا، که نوعی خطای منفی به حساب میآید، میتواند به نتیجه وخیمی مانند از دست رفتن یک عضو بدن منجر شود. خطاهای مثبت می توانند منجر به تجویز دارو و یا آزمایشات پزشکی شود که نیازی بدانها نبوده است.
البته، محل یک مسئله خاص نیز در این نمودار دوبعدی به صورت تابعی از تغییرات فنی و اجتماعی تغییر میکند. بهبود در قابلیت پیشبینیپذیری یک مسئله، که از دادههای بیشتر و الگوریتمهای بهتر ناشی میشود مسائل را به سمت راست نمودار سوق میدهد (این تغییر جایگاهها با پیکانهای افقی نشان داده شده است). بار مقررات اضافی میزان هزینه خطاها را افزایش داده و آنها را به سمت بالای نمودار سوق میدهد، در حالی که مقررات کمتر و یا کاهش مسئولیتها منجر به جابهجایی یک مسئله به سمت پایین نمودار میگردد (پیکانهای عمودی). تغییر در هنجارها و ارزشهای اجتماعی نیز منجر به تغییر در این نمودار خواهد شد. برای مثال از دست دادن حمایت افکار عمومی برای جنگندههای بدون سرنشین قطعاً در محل قرارگیری این فعالیت در روی نمودار تاثیر خواهد داشت.
این نمودار همچنین نمونههایی از جابهجایی چندین مسئله مختلف را همراه با "مرزهای احتمالی ماشینی شدن" بین مسائل تصمیمگیری مناسب انسان -و ماشین- نشان میدهد.
مرز ماشینی شدن (که با خطوط تقطه چین در نمودار مشخص شده است) یک خط شیبدار به سمت بالا است که مرز موجود میان قابلیت پیشبینی پذیری و میزان خطا قابل قبول را نشان میدهد. هزینه بالاتر به ازای هر خطا به یک سطح بالاتر از قابلیت پیشبینی پذیری در ماشینی شدن نیاز دارد. مرز منحنی شکل نمودار نسبت به حالت خطی نشاندهنده مرز دقیقتری میباشد.
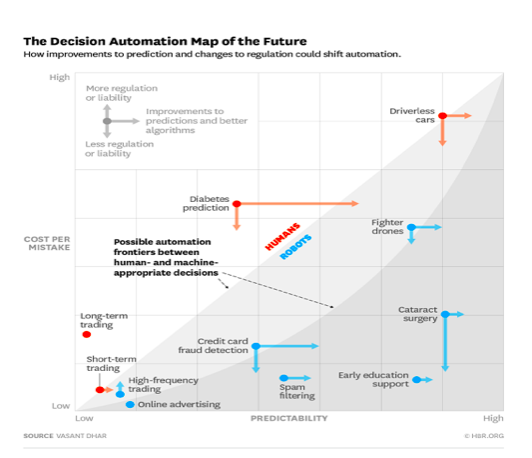
زیر مرز ماشینی شدن، چندین مسئله مانند معاملات متواتر و تبلیغات آنلاین را مشاهده میکنیم که در حال حاضر به دلیل هزینه کم هر خطا نسبت به مزایای تصمیمگیری قابل اعتماد و مقیاس پذیر، تا حد زیادی به صورت ماشینی و خودکار انجام میشوند. از طرف مقابل در قسمت بالای مرز منحنی شکل، متوجه خواهیم شد که حتی هنوز هم بهترین سیستمهای فعلی پیشبینی دیابت خطاهای مثبت و منفی زیادی ایجاد میکنند که هزینه ناشی از هر کدام برای توجیه استفاده تمام و کمال از سیستمهای خودکار بسیار بالاست. به همین دلیل است که هنوز هم به طور کلی پزشکان در تخمین خطر ابتلا به دیابت در بیماران دخیل هستند. از سوی دیگر، در دسترس بودن اطلاعات ژنتیکی و دیگر اطلاعات پزشکی فرد میتواند به طرز چشمگیری دقت پیشبینی را بهبود بخشیده (پیکان افقی نارنجی رنگ در شکل) و به ساخت رباتهای قابل اعتماد متخصص در مراقبتهای پزشکی در آینده نزدیک کمک کند. تغییرات در قابلیت پیشبینی پذیری و هزینه هر خطا میتواند یک مسئله را به ناحیه انجام توسط ربات، داخل و یا از آن خارج کند. برای مثال، با بهبود خودروهای بدون راننده و رضایت بیشتر ما از آنها، وضع قوانین جدید و رفع اشکال قوانین محدود کنندۀ استفاده از این نوع وسایل نقلیه میتواند به ظهور بازار بیمه در این حوزه کمک کرده و هزینه خطا را به شدت کاهش دهد.
تقشه تصمیمگیری اتوماتیک میتواند توسط مدیران، سرمایهگذران، قانونگذاران و سیاستگذاران برای پاسخگویی به سوالات در مورد تصمیمگیری خودکار استفاده شود. این نقشه میتواند به مردم در اولویتبندی طرحهای اولیه و برجستهکردن مسائلی که تخصص مورد نیاز برای انجام آنها، قابلیت یاد گرفته شدن توسط ماشینها را با حداقل برنامه نویسی قبلی داشته و هزینه خطای آنها نیز کم باشد کمک کند.
شاید بزرگترین چالش برای بهرهگیری ماشینهای یادگیری مبتنی بر داده، عدم قطعیت مرتبط با این موضوع باشد که آنها چگونه با موارد لبه مرزی که برای اولین بار با آن مواجه میشوند برخورد خواهند کرد. برای مثال موانعی که در مسیر خودرو بدون راننده گوگل وجود داشته و میتواند منجر به تصادفات جزئی شود.
انسان در مواجه با شرایط عجیب و غریب و یا جدید، به طور شهودی با استفاده از حواس پنجگانه تصمیمات متناسب با شرایط میگیرد. اما در صورتی که چنین شرایطی برای ماشینها رخ دهد در چگونگی رفتار آنها ابهام بزرگی وجود دارد. در چنین موارد حساسی، نتیجه میتواند بسیار بدتر از شرایط عادی باشد. هرچه عدم قطعیت یک مسئله بیشتر باشد ما ترجیح میدهیم که کمتر در تصمیمگیری هایی که به مسائل شهودی و حواس پنجگانه وابسته هستند از ماشینها استفاده کنیم.
برای جامعه نگرانی اصلی این است که آیا ماشینی شدن امور باعث از بین رفتن میلیونها شغل خواهد شد یا خیر. در اوایل دهه 1960 میلادی هربرت سیمون برنده جایزه نوبل اقتصاد، پیشبینی کرده بود که اگرچه بسیاری از تصمیمات "قابل برنامهریزی" در کسب و کار در دهههای آتی به صورت خودکار انجام خواهند شد، با این حال نگرانی در مورد " هیولای ماشینی شدن امور" بیمورد است. تاکنون پیشگویی سیمون در هر دو مورد صحیح بوده است، چرا که اگرچه ماشینی شدن فعالیتها بسیاری از موقعیتهای شغلی را از انسان ها سلب کرده، با این حال شغلها و سبک زندگی جدیدی را نیز برای انسانها ایجاد کرده است. با این وجود آنچه که به نظر میرسد باید در آینده نظارهگر آن باشیم این است که آیا نسل جدید ماشینها که قابلیت شنیدن، دیدن، خواندن و استدلال کردن دارند میتوانند بیش از آن که موقعیتهای شغلی انسانها را اشغال کنند موقعیتهای شغلی جدید ایجاد کنند یا خیر.
منبع: HBR.org
هنوز نظری وارد نشده است!
نظر خود را ارسال نمایید
پست الکترونیکی شما انتشار پیدا نمی کند.